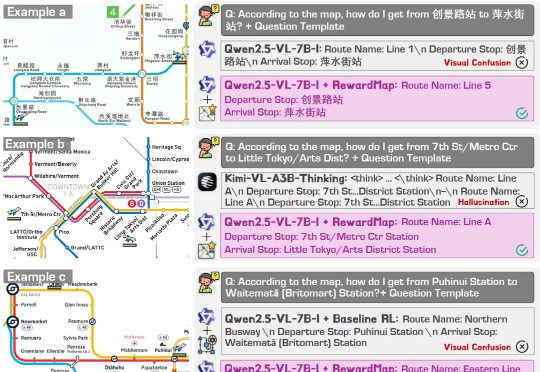
RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward RewardMap: 通过多阶段强化学习解决细粒度视觉推理的Sparse Reward 关键词: AI,模型训练,RewardMap,Sparse Reward 近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。 来自主题: AI技术研报 7413 点击 2025-10-21 15:53
 搜索
搜索